
金砖国家即将遭到报复?专家预测美国关税后果

Solana扩容主要基于:高效利用网络带宽、减少节点间通讯次数、加快节点运算速度 三大方面,这些措施直接缩短了出块和共识通讯的时间,但也降低了系统可用性(安全)。
Solana提前公开出块者Leader名单,揭示了单一可信的数据来源,缩减了共识通讯开销。但又会带来贿赂、针对性攻击等安全隐患。
Solana将共识通讯(投票信息)作为交易事件来处理,TPS成分中超过70%都是共识讯息,与用户交易相关的TPS约为500—1000;
Solana的Gulf Stream机制取缔了全局性交易池,这提高了交易处理速度,但降低了过滤垃圾交易的效率,Leader容易宕机。
Solana的Leader节点发布的是交易序列,而非真实的区块。结合Turbine传输协议,交易序列可以切碎后分发给不同节点,数据同步速度极快。
POH(Proof Of History)实质为一种计时和计数方式,它给不同的交易事件盖上序号,生成交易序列。Leader实质上在交易序列中发布了全网一致的计时器(时钟)。在很短的窗口期内,不同节点的账本推进、时间推移都是一致的;
Solana有132个节点占据67%的质押份额,其中的25个节点占据33%的质押份额,基本构成了“寡头政治”或“元老院”。如果这25个节点串谋,足以导致网络陷入混乱;
Solana对节点硬件水准要求很高,它以设备成本为代价,实现了纵向扩容。运行Solana节点的个体多为鲸鱼或机构、企业,不利于真正意义的去中心化。
综上,Solana以高级节点设备、颠覆性的共识机制与数据传输协议,将Layer1扩容推向了极端,基本触及无分片公链可维持的TPS瓶颈。但多次宕机已经预示了牺牲可用性/安全性来换取效率的结局。
2021年是区块链和Crypto的转折之年。随着Web3等概念成为显学,公链界迎来了有史以来最强劲的流量增长。在这样的外部环境下,以太坊凭借充分的去中心化和安全性,成为Web3世界的泰山北斗,但效率问题却成了它的“阿喀琉斯之踵”。相比于TPS轻松破千的VISA,每秒10几笔交易的以太坊宛若怀中襁褓,与其“世界级去中心化应用平台”的宏大愿景相差甚远。
对此,Solana、Avalanche、Fantom、Near等以扩容为核心的新公链一度成为Web3叙事的主要角色,获得了巨量资本的垂青。仅以Solana为例,这个号称“以太坊杀手”的头部公链在2021年市值飙涨170倍,如日中天,甚至一度超越老牌公链Polkadot和Cardano,大有和以太坊争雄的势头。
但在2021年9月14日,Solana因为性能上的问题,首次迎来宕机事故,时间长达17小时,SOL代币价格随之快速下跌15%;2022年1月,Solana再次出现宕机,时长足有30小时,引发了极为广泛的讨论;之后的5月,Solana先后宕机2次,6月初又宕机1次。根据Solana官方的说法,其主网至少经历了8次性能下降或是宕机事故。
伴随着诸多问题的出现,以太坊支持者为首的批评者轮番对Solana提出质疑,有人甚至给Solana冠以“SQLana”的称号(SQL是管理中心化数据库的系统),并先后产生了大量的评论与分析。时至今日,关于Solana真实可用性的讨论似乎从未停止,吸引着无数好奇心浓重的观察者。出于对主流公链的兴趣与关注,CatcherVC将从自身视角出发,在本文对Solana扩容机制及其宕机的部分原因展开简单解读。
公链的效率主要指其处理交易的能力,也就是吞吐量TPS(每秒处理的交易笔数),这个指标受到出块速度和区块容量的影响,同时也影响着交易手续费和用户活跃度。从2018年甚嚣尘上的EOS,到近期发币的Optimism,所有扩容方案几乎都绕不开“加速出块”这个最关键的要素。
要提升出块速度,往往要在出块流程上“做手脚”,Solana也不出其右。其扩容方式主要立足于 高效利用网络带宽、减少节点间通讯的次数、提高节点处理事务的速度 三大方面,这些措施直接缩短了出块和共识通讯的时间。Solana的创始人Anatoly Yakovenko及其队友对每一个细节都进行了精心雕琢,以系统的可用性(安全)为代价,尽可能在效率上作出提升,基本达到了无分片公链的实际TPS极限,最终作出了“有代价”的创新。
相比于其他采用POS的公链,Solana最大的创新点在于其独特的共识协议和网络节点通信方式,该共识协议基于POS和PBFT(实用拜占庭容错),引入独创的POH(Proof of History)作为推进区块链账本的机制,独树一帜的创建了自己的共识体系。
单从表现形式的角度看,Solana的共识协议与Cardano最早的Ouroboros(衔尾蛇)算法类似,都包含Epoch(纪元)和Slot(间隔)两大时间单位。每个Slot约为0.4~0.8秒,相当于一个区块的时间间隔。而每个Epoch周期包含43.2万个Slot(区块),长达2~4天。
在Solana的系统架构中,最重要的角色分为两类:Leader(出块者)和Validator(验证者)。两者实际上都是质押了SOL代币的全节点,只是在不同的Slot(出块周期)内,Leader会由不同的全节点来充当,而没有当选Leader的全节点会成为Validator。
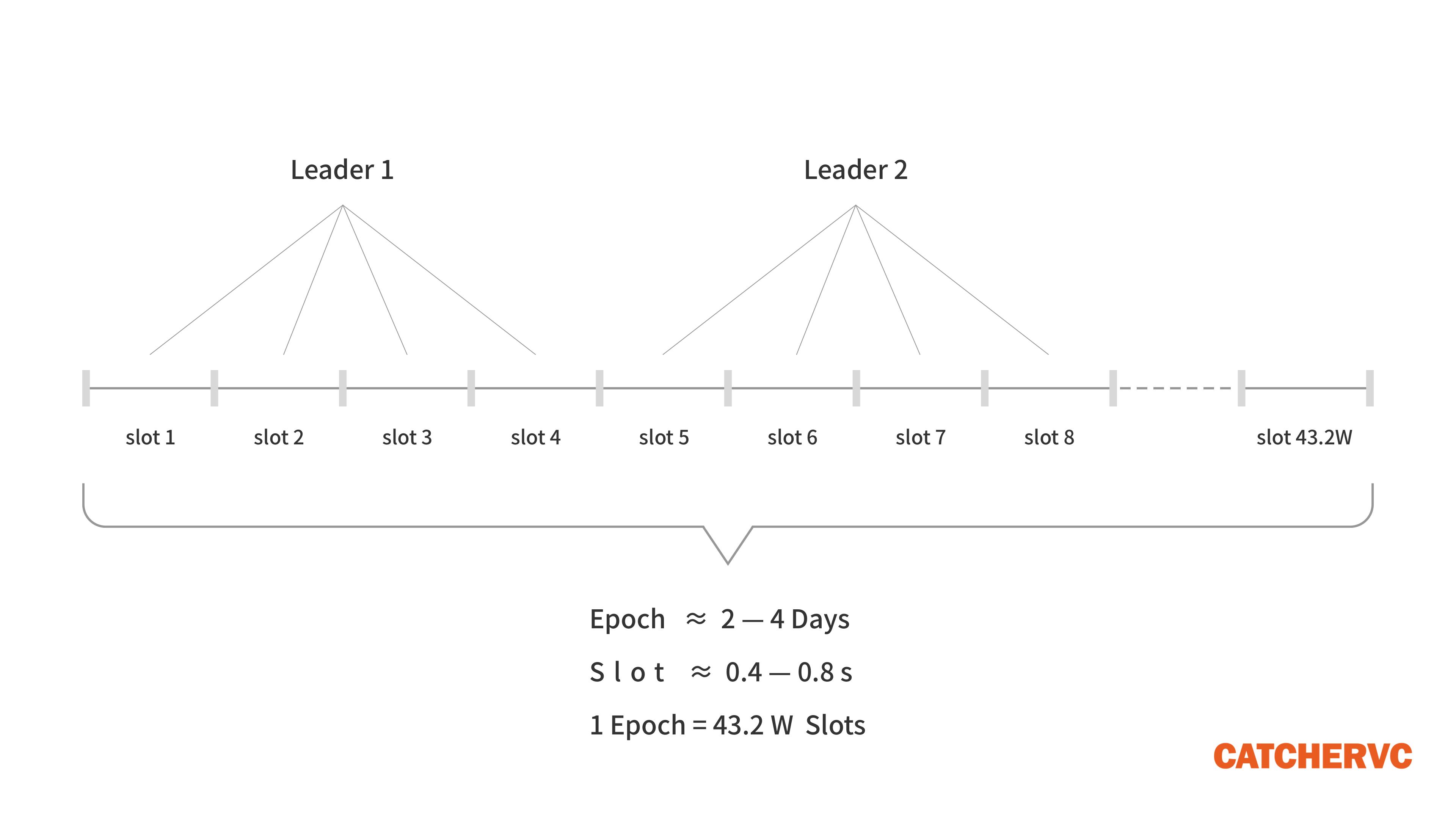
在每个新的Epoch周期开始时,Solana网络会按照各节点的质押权重进行抽选,组成一个出块者Leader轮换名单,“钦定”了未来不同时刻的出块者。在整个Epoch(2~4天)内,出块者会按照名单指定的次序进行轮换,每过4个Slot(出块周期),Leader节点就会进行一次变更。
由于提前公开了未来的出块节点,Solana网络实质获得了确定而可信的新区块数据源,为共识过程提供了巨大便利。
为了更清晰的理解Solana的扩容机制,我们不妨从出块逻辑开始,对Solana的大致结构进行解析:
1.用户发起交易后,会被客户端直接转发给Leader节点,或者先被普通节点接收,再立刻转发给Leader;
2.出块者Leader接收网络内全部的待处理交易,一边执行,一边给交易指令排序,制成交易序列(类似区块)。每隔一段时间,Leader会把排好的交易序列发送给Validator验证节点;
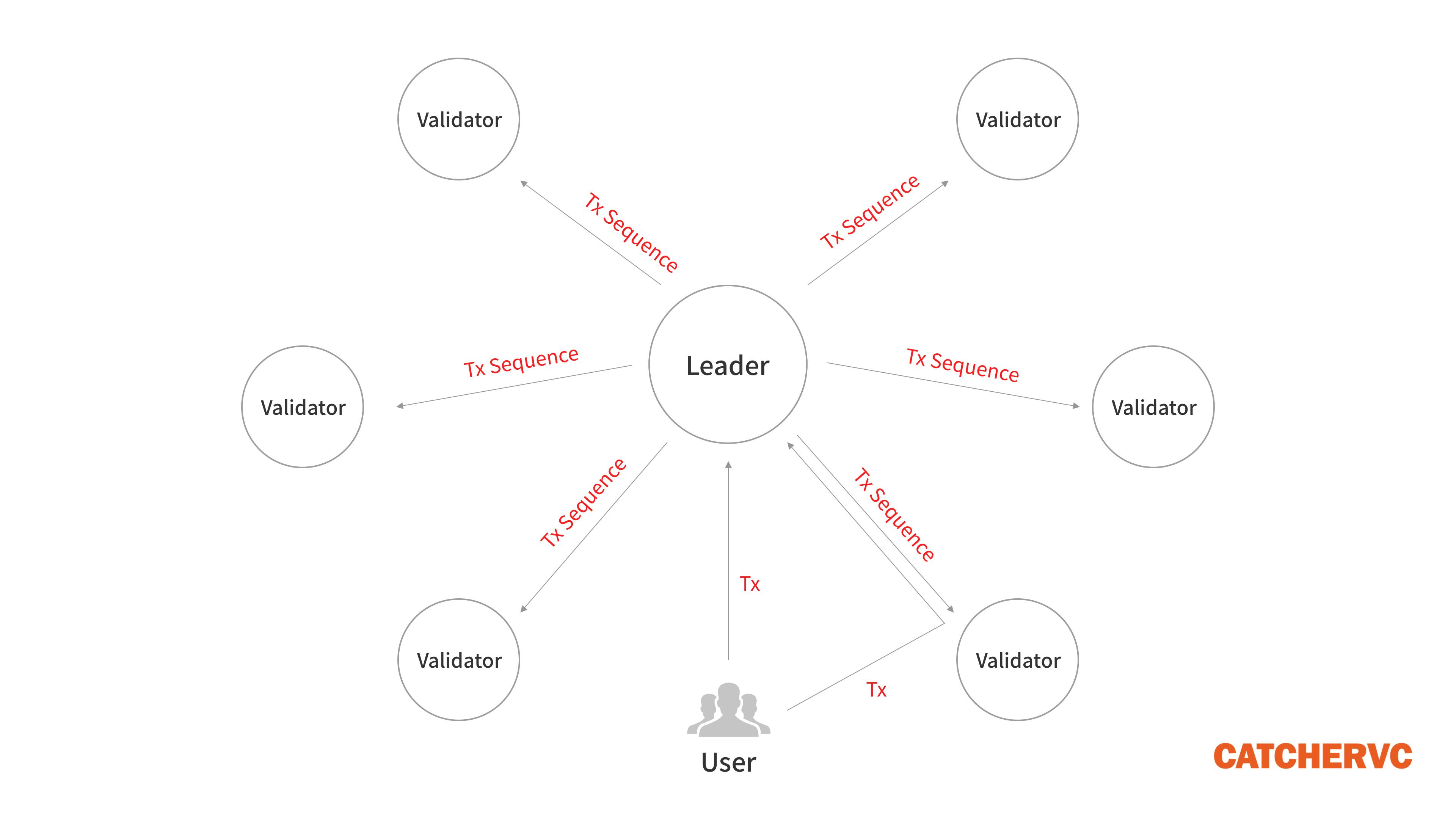
3.Validator按照交易序列(区块)给定的顺序执行交易,产生相应的状态信息State(执行交易会改变节点的状态,比如改变某些账户的余额);
4.每发送N个交易序列,Leader会定期公开本地的状态State,Validator会将其与自己的State作对比,给出 肯定/否定 的投票。这一步就类似于以太坊2.0或其他POS公链里的“检查点”。
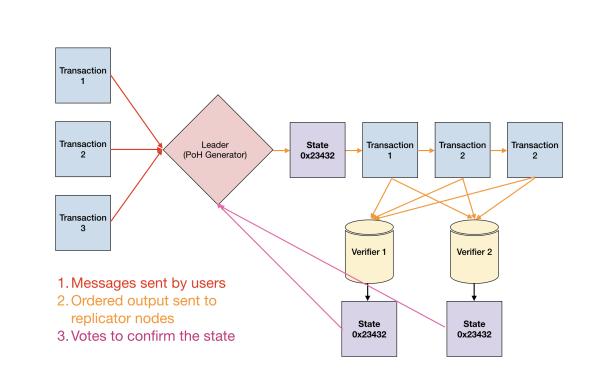
5.如果在规定时间内,Leader收集到占全网 2/3质押权重 的节点们给出的肯定票,则此前发布的交易序列和状态State就被敲定,“检查点”通过,相当于区块完成最终确认Finality;
6.一般而言,给出肯定票的Validator节点与出块者Leader所执行的交易、执行后的状态都是相同的,数据会同步。
7.每过4个Slot周期,Leader会进行一次切换,这意味着Leader每次大概有1.6秒~3.2秒时间掌握网络的“最高话语权”。
表面看来,Solana的出块逻辑与其他采用POS机制的公链大体一致,都有一个发布区块、对区块投票的过程。但如果我们对每一个步骤都展开观察,不难发现Solana与其他公链之间有着天壤之别,而这正是其高TPS、低可用性的根源所在:
1.最重要的一点:Solana提前公开每个周期Slot的出块者Leader,大幅减少了共识过程的工作量。在其他POS公链中,由于缺乏单一的、可信的出块节点,网络的共识通讯效率极低,产生的时间复杂度往往比Solana高出几个数量级,这成为了多数公链在TPS上的瓶颈。
以主流的POS共识协议或PBFT算法为例,这些算法大多采用了和Solana相同的时间单位与角色划分,也有类似于Epoch纪元、Slot区块周期、Leader出块者、Validator验证者、Vote投票 的设定,只是参数设置和叫法不同而已。最大的不同在于,此类算法大多以安全性(可用性)为前提,不会提前公开Leader名单。
由于没有公开的出块者,节点间会“互不信任”并“各自为政”。此时,若某个节点自称为合法出块者,大家并不敢信任他,必须要其出示相关的Proof证明才行。但此类Proof证明的生成、传播、验证会浪费带宽资源,并产生额外的工作量(甚至会和ZK零知识证明扯上关系)。Solana公开每个时段的Leader,可以避免此类麻烦。
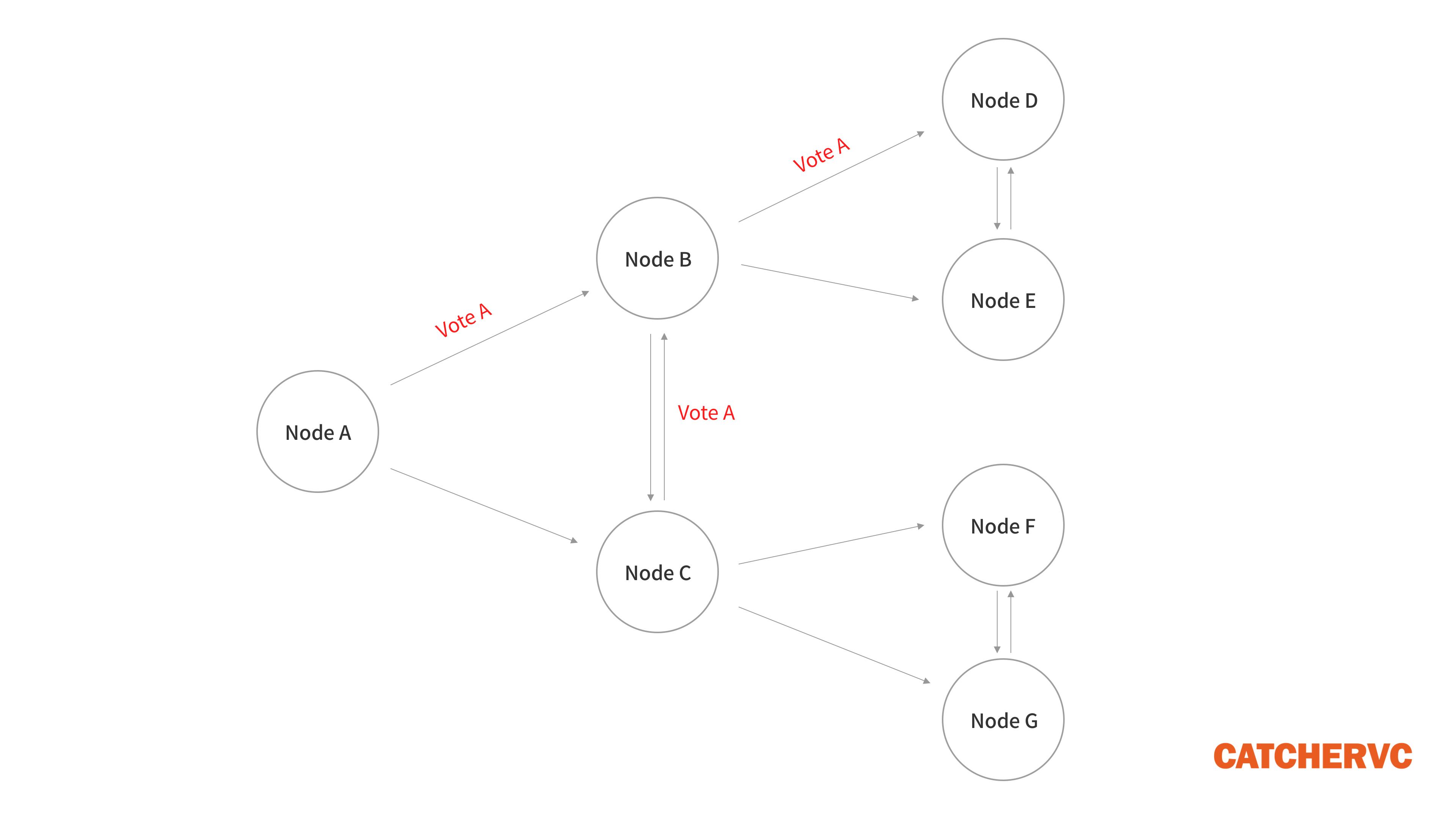
更为重要的是,在绝大多数POS共识协议或PBFT类算法中,针对新区块的投票Vote(一个区块要得到网络内2/3节点的肯定票才能敲定),往往由各个节点通过“流言协议”,以类似1对1交流的方式发送或收集,有点类似于病毒式随机扩散,实质等价于 每两个节点间都要通讯一次,其复杂度和耗时远高于Solana的共识协议。
在Tendermint等PBFT算法中,单个Validator节点至少要收集网络内2/3的节点发出的单张投票。如果全网节点数量为N,则每个节点至少接收2/3×N个投票,整个网络产生的通讯次数至少为2/3×N²,显然这个数量级太大了(和N的平方成正比)。如果节点数量很多,其共识过程的耗时往往会陡增。
对此,Solana和Avalanche以不同的方式改良了节点收集投票的通讯过程,降低了时间复杂度。通俗的讲,Leader集中汇总所有Validator发出的投票,再把这些投票打包在一起(写进交易序列里),一次性推送到网络中。
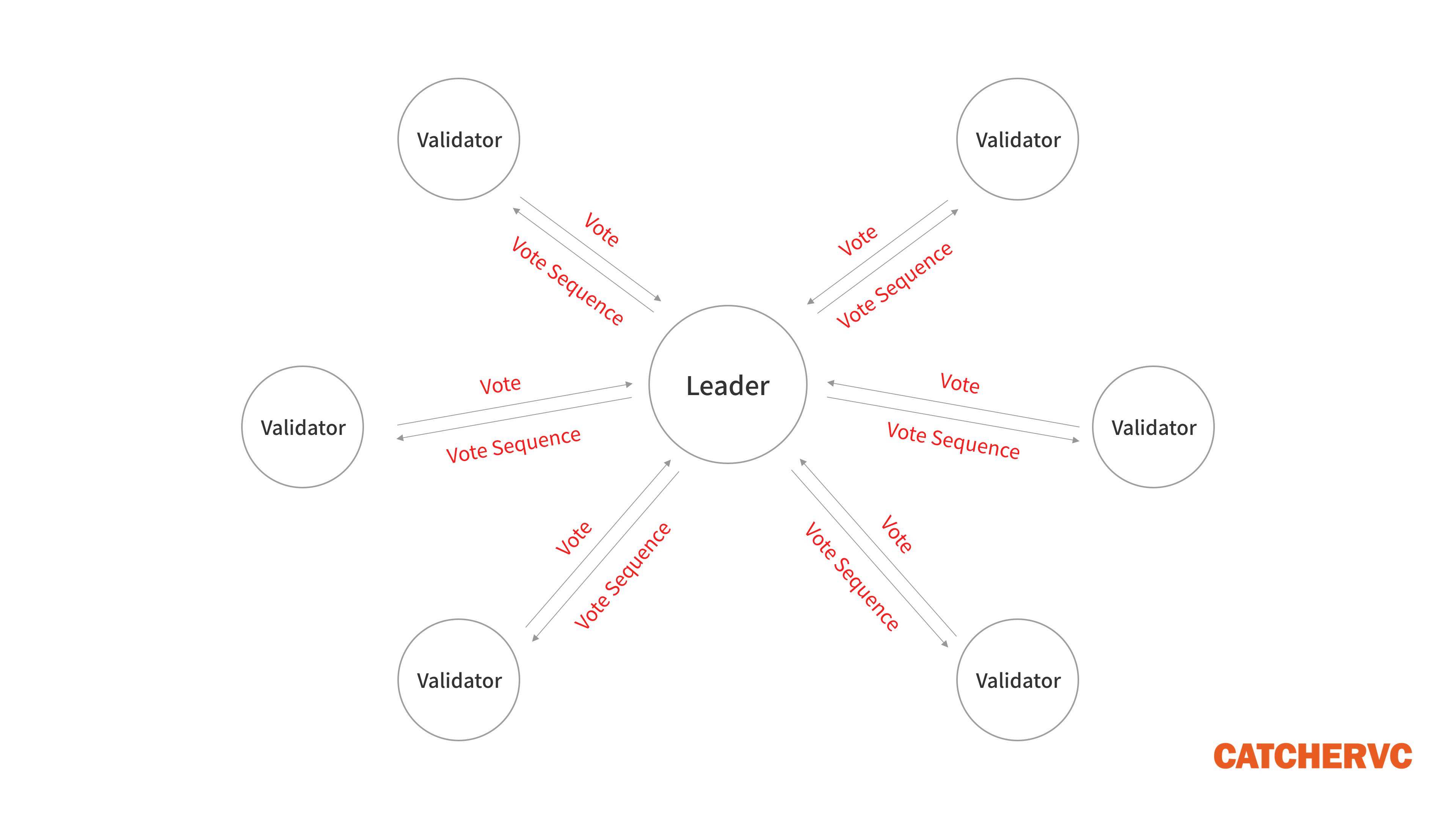
这样一来,节点们无需再通过“流言协议”频繁的、1个1个的互换投票信息,通讯次数降低到了常数N甚至是logN的数量级,这在很大程度上缩短了出块时间,大幅提高了TPS。
目前Solana出块周期基本和单个Slot的时长一致,为0.4~0.8秒,甚至比Avalanche还快出3倍。(Solana浏览器显示的区块,实质是每个Slot内Leader发布的交易序列)。
但这也带来了另一个问题:由Leader在交易序列(区块)内发布节点们的投票信息,会占用区块空间。在Solana的设定中,Leader实质将共识投票作为一种交易事件来处理,其发布的交易序列包含节点投票Vote,而这些投票正是Solana TPS的主要成分(一般占70%以上)。
按照Solana浏览器里的数据统计,其实际TPS维持在2000~3000左右,其中70%以上是与普通用户无关的共识投票讯息,与用户交易相关的实际TPS维持在500~1000,虽然比BSC和Polygon、EOS等高性能公链还高出1个量级,但仍无法达到官方所鼓吹的上万级别。
同时,如果Solana未来不断的提升去中心化程度,允许更多的节点参与共识投票(目前有近2000个Validator),则Leader发布的交易序列中必将包含更多的投票讯息,会持续压缩与用户交易相关的TPS空间。这标志着Solana在不分片的前提下,基本难以取得更高的TPS。
某种程度来看,Solana每秒500~1000笔的交易处理能力已达到无分片公链的巅峰,在节点数量较多、不分片且支持智能合约的前提下,新公链基本难以超越Solana的TPS量级,除非它们采用“委员会”模式,只允许少量节点参与共识,或者退化为中心化服务器。只要参与共识的节点数量很多,就难以取得比Solana更高的“可证实的TPS”。
格外值得注意的是,由于每个Epoch内(2~4天)的出块者名单是提前公开的,Solana的共识协议与原始的Tendermint算法并无本质区别,实际都没有赋予出块者以不可预测性,所有人都能预知未来某个时间点由谁来出块,这就会在 可用性/安全性 上产生诸多隐患。
(Leader易遭遇有预谋的DDOS攻击,提高了故障率,若连续几个Leader出现故障,则网络容易宕机;且用户可提前贿赂Leader等)
2.Gulf Stream与网络宕机:Solana公开出块者Leader名单还有一个更重要的目的:配合其独创的Gulf Stream(海湾流)机制,提高网络处理交易的速度。

用户发起交易后,往往被客户端程序直接转发给指定的Leader,或者先被某个普通节点接收,再被该节点快速发送给Leader。这种方式可以让Leader尽快接收交易请求,提高响应速度。(称为Gulf Stream机制,是Solana宕机的主因之一)
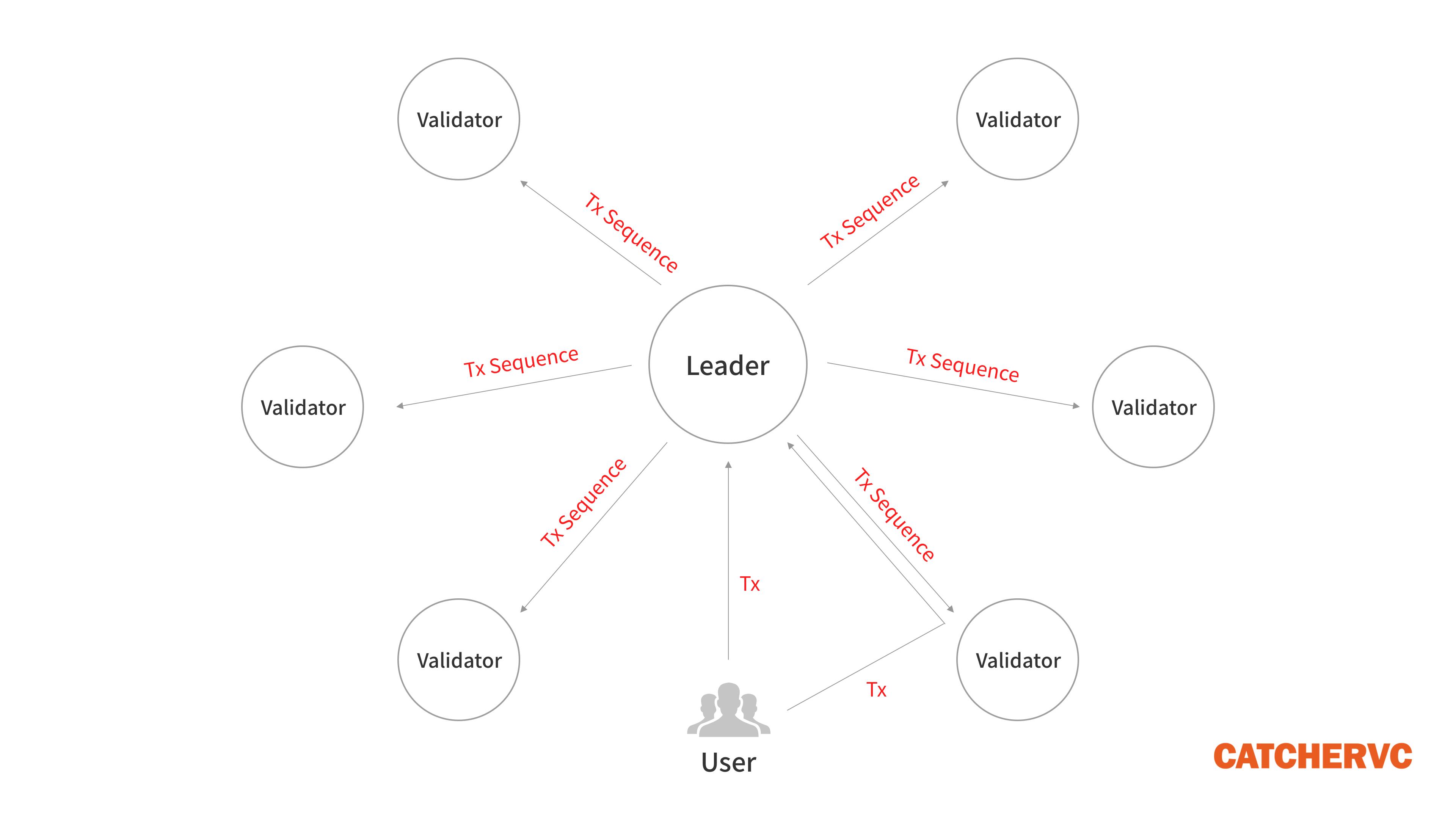
Solana的这种设定,是与其他公链截然不同的交易提交方式。Gulf Stream取缔了比特币和以太坊的“全局交易池”设定,普通节点不运行大容量的交易池。一个节点收到用户的待处理交易后,只需交给Leader,不必再发给其他节点,这种做法大幅提高了效率,但由于取缔了交易池,普通节点无法高效拦截垃圾交易,容易导致Leader节点宕机。
为了深刻理解这一点,我们可以对比ETH:
·以太坊的每个全节点都有名为交易池(内存池)的存储区域,用于存放未上链、待处理的交易指令。
·当节点接收到新的交易请求后,会先进行过滤,判断交易指令是否合规(是否为重复/垃圾交易),之后将其存入交易池,再转发给其他节点(病毒式扩散)。
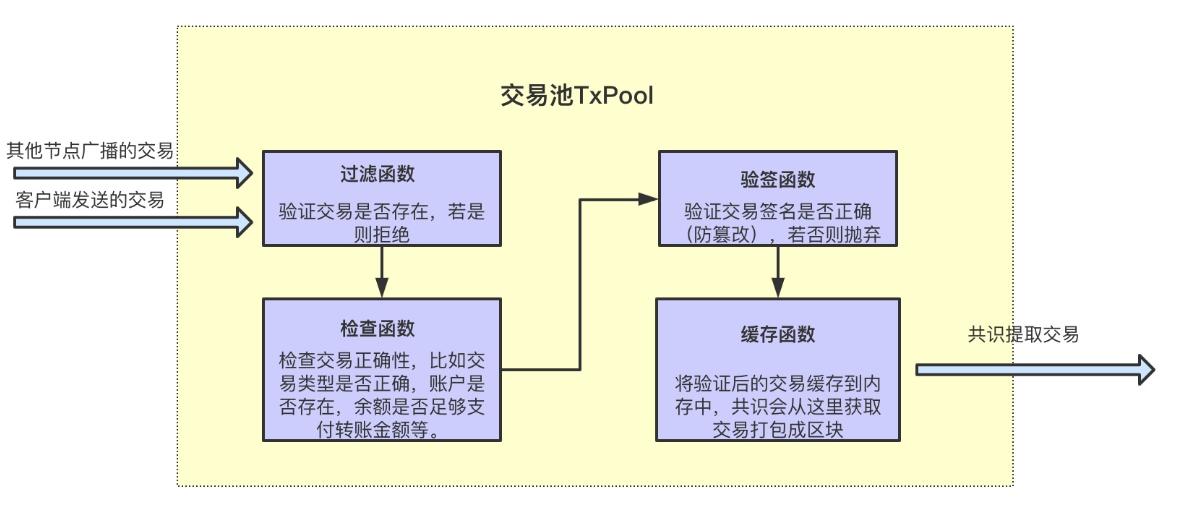
·最终,一笔合法的待处理交易会传遍网络,放入所有节点的交易池里,这就让不同节点都获取到相同的数据,表现出“一致性”。
以太坊和比特币采取这种机制,理由很明确:不知道未来的出块者是谁,所有人都有概率打包新区块。所以,必须让不同节点接收到相同的待处理交易,为打包区块做准备。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。本站资讯仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。
industry-frontier

